文|异观财经 炫夜白雪
作为今年上半年最火的创业赛道,大模型已经堪称“百模大战”。根据中国科学技术信息研究院《中国人工智能大模型地图研究报告》,截至5月28日,国内10亿级参数规模以上大模型,至少已经发布了79个。最近看一篇报道,里面提到一个数据,国内市场上已有130家公司在做大模型。
以终为始。从投资角度来看,预判大模型的终局是什么样的,才能有助于我们去思考市面上的哪些公司值得看好。从电商平台大战一路看过来(有谁还记得想做平台最后一地鸡毛的凡客吗?),在科技赛道,绝大多数时候轰轰烈烈的“百云大战”“千团大战”,99%玩家是黯然退出,只剩下赢家通吃。
纵观这些年的赢家通吃赛道,基本可以用两个词概括:新平台、新基建。如何理解呢?通常这类玩家,为一个产业提供了新的平台,通过技术变革的方式建立起产业新的基础设施——类似高速公路、水电气等基建,让原有的产业链参与者能够加入到新平台来,享有技术变革的红利。
什么是大模型?第一,顾名思义是规模大,网络参数达到百亿规模;第二,通用性,是指不限于专门问题或领域;第三,涌现性,即产生预料之外的新能力。大模型的大规模和通用性,决定了其将是具备普适性的“新平台、新基建”,其从一个行业迁移到另一个行业的应用场景时,成本低,易迁移。
可以断言,放在大模型这一赛道,依然将是赢家通吃的终局。
那么,现在“百模大战”的玩家里,谁将笑到最后?大体来分,目前大模型的玩家有两类,一类是大厂拉起的团队,另一类是创业公司。这里可以有把握地说,在这个百模大战中,大厂优先。
我们可以参考另一个行业云计算的发展走向。当年云计算兴起的时候,国内也出来很多创业公司玩家,但最终市场份额集中于大公司。根据IDC发布的2022年全球云计算IaaS市场追踪数据来看,市场份额TOP10玩家都是中美的大公司,包括美国的亚马逊、谷歌、微软、IBM,中国的阿里、华为、腾讯、百度等。
后面我们会进一步分析。不过这里先看看制约大模型的三个要素:数据、算力和算法。
先说数据。
数据是大模型发展的压舱石,除了互联网、物联网数据之外,老百姓生活生产中产生的数据都是未来大模型要提升智能水平的必要数据源。目前,数据壁垒是真实存在的问题。高质量的中文语料数据对于创业公司来说是个很大的挑战,数据的积累需要时间和经验。对于像百度这样常年累月通过搜索等多个互联网、物联网应用积累起数据的公司来说,可以说一开始就领先了至少几个身位。
给AI喂下什么质量的数据,才能训练和迭代出什么水平的AI。
再说算力。
通用大模型需要24×7连续训练,调度多个算力中心、协调资源,以云的方式提供智能服务,这对算力有很大的需求。随着参与大模型训练的企业越来越多,用来训练大模型的数据量越来越大,对推理的要求也越来越高,大模型的应用会越来越广。在以上因素综合影响下,短期内很难能够满足市场的算力需求。
这就意味着,大模型公司必须拥有稳定的、靠谱的、能保障安全运转的算力。这显然利于在云计算深耕布局的大厂。
当年云计算创业公司,面临大厂的夹击,窄缝求生,专攻一个垂直行业的云计算市场——比如游戏行业。但是,游戏行业遭遇监管重创的时候,云计算需求也大大降低,这导致该云计算创业公司的业务不稳定,反过来又影响使用该家公司服务的客户。
这也是为什么大模型和云计算同样是赢家通吃的原因之一——大玩家能够提供更为稳定、可靠的服务,成为客户的优先选择。
最后说算法。
大模型最底层的竞争力来自算法。算法需要庞大的高级人才和长期积累。相比百度这样长期投入 AI 的高科技企业,后来者就缺乏相应的储备了。
为什么现在看起来有很多的公司做大模型呢?因为现在有开源的大模型和很多公开的论文可供参考,所以起步上会简单很多。但要做好大模型的门槛还是高的,像现在的GPT4没有公开后续技术细节,国内很多大模型就很难继续发展。
在SuperCLUE不久前发布的最新测评榜单中,可以看到,凭“硬实力”说话,还是大厂更胜一筹,其中百度最新版本的文心一言,在中文领域已经超过了GPT-3.5,仅次于GPT-4。
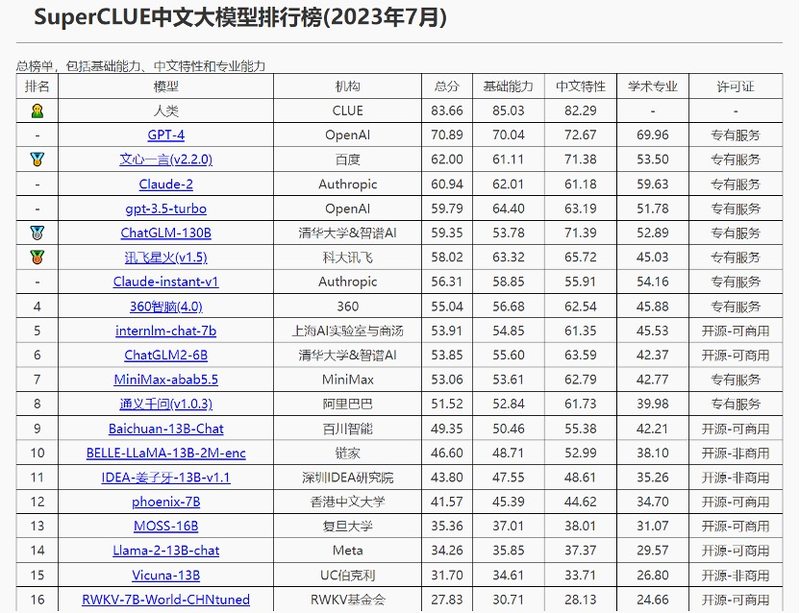
IDC发布的《AI大模型技术能力评估报告2023》中,就围绕着产品技术、服务生态以及行业应用三大维度,考察大模型的10余项指标,对国内主流大模型进行评估。其中,百度文心大模型获得综合评分、算法模型、行业覆盖等多项第一。在服务能力、生态合作等方面,几大主流大模型也可谓是各有千秋。
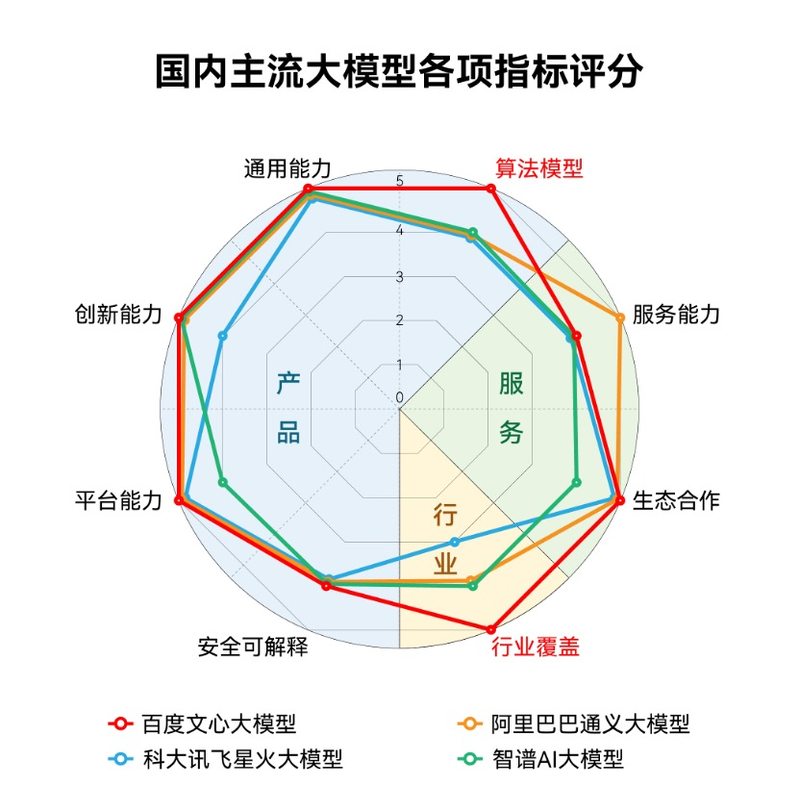
这无疑体现了,大厂在大模型竞赛中的绝对优势。在产品技术和行业应用上,远胜过二三线的竞品。比如排名第一的文心大模型,据其官方透露,已经有15万家企业申请接入文心一言测试,百度智能云与300多家生态伙伴,在超过400个场景中已取得相当不错的测试效果,并联合多家企业单位合作发布了11个行业大模型。
越多的应用场景,能形成越多的反馈,从而对模型进行更好的调整;而模型也因此产生更多的经济价值,可获得更多的资金投入,反哺自身。
需要指出的是,大模型高昂的训练成本和研发投入,让众多入局者望而生畏。有企业家断言,每年5000万到1亿美元的花费,只是千亿级大模型训练的入场券。某个创业者高调宣布投资5000万美元入局大模型时,海通证券的电子研究首席分析师郑宏达发朋友圈直言说:“5000万美元够干什么的?大模型训练一次就花500万美元,训练10次?”四个月之后,该创业公司被收购,出局。
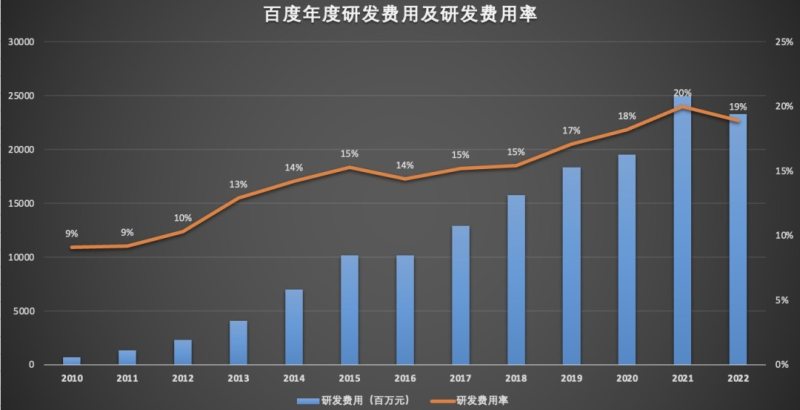
当年共享单车也是百团大战,打得头破血流,结果笑到最后的是美团。无他,资金充足。在以年计、甚至以十年计的竞争中,这种重资本重研发的赛道,毫无疑问是利于大公司的。在大公司中,我们还要看人工智能是不是公司的主业,是不是公司的核心竞争力所在。比如百度10年研发,为人工智能投入上千亿元。从近三年的研发投入来看,2020年研发费用为195.1亿元,研发占比为18.2%;2021年研发费用为249.4亿元,研发占比为20%;2022年百度研发费用为233.2亿元,研发占比为19%。
这是一场漫长的、看不到终点的长跑,竞争的韧性将左右最后的结果。
需要额外指出的是,人工智能对数据的需求以及其对人类社会的冲击力,使得国家监管会成为一个很重要的考虑因素。7月13日,国家网信办、发改委、科技部、工信部等七部门正式发布了《生成式人工智能服务管理暂行办法》(以下简称“《办法》”),《办法》将自2023年8月15日起施行。其中提出国家坚持发展和安全并重、促进创新和依法治理相结合的原则,采取有效措施鼓励生成式人工智能创新发展,对生成式人工智能服务实行包容审慎和分类分级监管。
在 2023WA-IC 期间,由国家标准委指导的人工智能标准化总体组宣布,我国首个大模型标准化专题组组长由上海人工智能实验室与百度、华为等企业联合担任,现场进行了证书颁发并正式启动大模型测试国家标准制订工作。在“百模大战”的现状下,此举被解读为大模型行业迎来“国家队”阵容。
以赢家通吃的终局为前提下,我们判断是,在仅有几家通用大模型的基础上,将有多个领域的垂直大模型。龙头企业研发通用+中小企业研发应用,这种模式成为破局关键。