文丨自象限 罗辑
编辑丨程心
AI原生应用,“难产”了。
百模大战后,一众精疲力竭的创业者们逐渐反应过来:中国真正的机会在应用层,AI原生应用才是下一轮最肥沃的土壤。
李彦宏、王小川、周鸿祎、傅盛,盘点过去几个月的大佬发言,无一不在着重强调应用层的巨大机遇。
互联网巨头们把AI原生挂在嘴边:百度一口气发布超20款AI原生应用;字节跳动成立了新团队,主攻应用层;腾讯将大模型嵌入了小程序;阿里也要用通义千问将所有应用重新做一遍;Wps疯狂赠送AI体验卡..
创业公司更是狂热,一场黑客马拉松下来,近乎200个AI原生项目。今年以来,包括奇绩创坛、百度、Founder Park大大小小加起来,数十场活动,上千个项目,最后却没有一个跑出来。
不得不正视的是,尽管我们意识到了应用层的巨大机遇,但大模型并没有颠覆所有应用,所有产品都在不痛不痒地改造。尽管,中国有最优秀的产品经理,但他们这回也“失灵”了。
从4月份Midjourney爆火,到现在,9个月的时间,汇集了“全村人希望”的国产AI原生应用,究竟为何难产?
选择比努力更重要,在当下,或许我们更需要冷静回望,寻找正确打开AI原生应用的“姿势”。
一、做AI原生,不能端到端
原生应用为何难产?我们或许可以从原生应用的“生产”过程中找到一些答案。
“我们通常会同时跑四五个模型,哪个性能更优就选择哪个。”硅谷的一位大模型创业者在与「自象限」交流时提到,他们基于基础大模型开发AI应用,但前期并不绑定某一个大模型,而是让每一个模型都上来跑一跑,最终选择最合适的那个。
简单来说,赛马机制如今也卷到了大模型身上。
但这种方式其实仍存在一些弊端,因为它虽然选择了不同大模型进行尝试,但最终还是会与其中某一个大模型进行深度耦合,这还是一种“端到端”的研发思路,即一个应用对应一个大模型。
但与应用不同,作为底层大模型,它同时又却会对应多个应用,这就导致了同一个场景下的不同应用之间,最后的差异十分有限。而更大的问题在于,目前市场上的基础大模型都各有所长的同时也各有所短,还没有某个大模型成为六边形战士,在所有领域遥遥领先,所以这导致基于一个大模型开发的应用最终难以在各个功能上实现平衡。
在这样的背景下,大模型与应用解耦就成了一种新的思路。
所谓“解耦”其实分为两个环节。
首先是大模型与应用解耦。作为AI原生应用的底层驱动力,大模型和原生应用之间的关系其实可以和汽车行业进行类比。
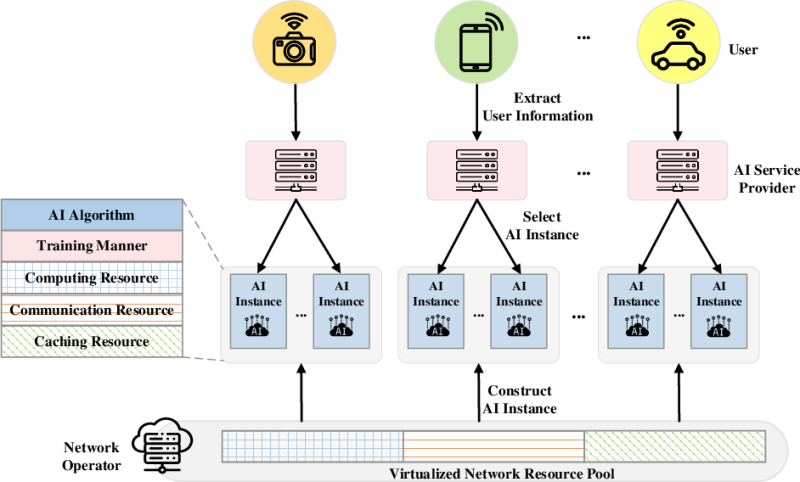
对于AI原生应用来说,大模型就像是汽车的发动机。同样一款发动机可以适配不同的车型,同一款车型也可以匹配不同的发动机,通过不同的调教,可以实现从微型车到豪华车的不同定位。
所以对于整车来说,发动机只是整体配置的一个部分,而不能成为定义整辆汽车的核心。
类比到AI原生应用,基础大模型是驱动应用的关键,但基础大模型并不应该与应用实现完全绑定。一个大模型可以驱动不同的应用,同一个应用也应该可以由不同的大模型进行驱动。
这样的例子其实在目前的案例中已经有了体现,比如国内的飞书、钉钉,国外的Slack,都可以适配不同的基础大模型,用户可以根据自身需要进行选择。
其次是在具体的应用当中,大模型与不同的应用环节应该层层解耦。
一个典型的例子是HeyGen,这是一家在国外爆火的AI视频公司,它的年度经常性收入在今年3月份就达到了 100万美元,并在今年11月达到1800 万美元。
HeyGen 目前拥有 25 名员工,但它已经建立了自己的视频 AI 模型,并同时集成了 OpenAI 和 Anthropic 的大型语言模型 和 Eleven Labs 的音频产品。基于不同的大模型,HeyGen制作一个视频就会在创作、脚本生成(文本)、声音等不同的环节用上不同的模型。
图源HeyGen官网
另一个更直接的案例是ChatGPT的插件生态,最近国内剪辑应用剪映加入了ChatGPT的生态池,在这之后,用户在ChatGPT上要求调用剪映的插件制作视频,剪映就能在ChatGPT的驱动下自动生成一个视频。
也就是说,大模型与应用的多对多匹配,可以精细到在每一个环节选择一个最适配的大模型进行支持。即一个应用不是由一个大模型进行驱动,而是由数个,甚至一组大模型进行联合驱动。
多个大模型对应一个应用,集百家之长。在这样的模式下,AI产业链的分工也将被重新定义。
如同当下的汽车产业链,发动机、电池、配件、机身每一个环节都有专门的厂商负责各司其职,而主机厂只需要进行选择和组装,形成差异化的产品,同时推向市场。
重新分工,打破重组,不破不立。
二、新生态的雏形
多模型多应用的模式下,将会催生一个新的生态。
按图索骥,我们试图根据互联网的经验来设想一下新生态的架构。
小程序诞生伊始,所有人对小程序的能力、架构、应用在哪些场景都十分迷茫,前期靠一个个企业从头开始学习小程序的能力与玩法,小程序的发展速度十分缓慢,数量始终无法突飞猛进。
直到微信服务商的出现,服务商们一手对接微信生态,熟悉小程序的底层架构和格局,一手对接企业客户,帮助客户根据需求打造专属小程序,同时配合整个微信生态的玩法,通过小程序进行获客和留存。服务商群体,也跑出了微盟和有赞。
也就是说,市场可能不需要垂类大模型,但需要大模型服务商。
同理,每一个大模型需要真正使用和操盘后才能真的了解相关的特性以及如何发挥,服务商在中间层,既可以向下兼容多个大模型,又能够与企业共创,打造一个良性的生态。
按照以往的经验,我们可以把服务商粗略地分为三大类:
第一类经验型服务商,即了解和掌握每一个大模型的特点和应用场景,配合行业的细分场景,通过服务团队打开局面;
第二类资源型服务商,如同彼时的微盟能够拿到微信内的低价广告位再外包出去的商业模式,未来大模型的开放权限并不是普世化的,能够拿到足够权限的服务商,将铸就前期壁垒;
第三类技术型服务商,当一个应用的底层同时嵌入不同大模型,如何将多模型进行调用和串联,同时保证稳定性,保证安全性,以及各类技术难题都需要技术服务商解决。
据「自象限」观察,近半年已经有大模型服务商的雏形开始出现,不过是以企业服务的形式,向企业进行各类大模型如何应用的教学。而做应用的方式也在慢慢形成WorkFlow。
“我现在做一个视频,先跟Claud提出一个剧本的想法让它帮我写成一段故事,再复制粘贴进ChatGPT里,利用它的逻辑能力分解成脚本,接入剪映插件文转视频直接生成视频,中间的一些图片如果不精准,用Midjourney重新生成,最后完成一个视频。如果一个应用能够同时调用这些能力,那就是一个真正原生的应用了。”一位创业者对我们讲到。
当然,多模型多应用的生态真正落实有很多难题需要解决,比如多个模型之间如何互通?如何通过算法实现模型调用的最大化?怎么配合才是最佳的解决方案,这些既是挑战,也是机遇。
从过往的经验来看,AI应用的发展趋势,可能会是,分散、点状的出现,然后逐渐被统一,集成。
比如,我们需要问答、做图、做PPT,现阶段可能是许多个单独的应用,但未来可能会被集成为一个整体的产品。向平台化靠拢。比如此前的打车、外卖、订票等多个业态,现在逐渐集中成一个超级APP里,不同的需求也会对模型能力提出进一步多元化的挑战。
除此之外,AI原生更会颠覆当下的商业模式,产业链上的热钱将进行重新分配,百度变成了知识的货架,阿里变成商品的货架,所有的商业模式回归到最本质的部分,满足消费者的真实需求,冗余的流程就被取代了。
在此基础上,价值创造是一方面,如何重新构建商业模式,成为投资人和创业者需要思考的更重要的问题。
当下,我们仍处在AI原生应用的爆发前夜,当逐渐形成了底层是基础大模型,中层是大模型服务商,上层是各类创业公司。如此层层分工分明,良性协作,AI原生应用才能批量到来。