文|市值榜 武占国
编辑|何玥阳
火了一年多的大模型,步入到了我们熟悉的、国内大厂擅长的经典剧情——价格战。
近日,阿里、字节、腾讯等模型厂商相继推出新模型,并宣布降价。
5月6日,国内知名私募巨头幻方量化旗下AI公司,发布DeepSeek-V2大模型,价格为GPT-4 Turbo的近百分之一;
5月9日,阿里发布通义千问2.5,个人用户可从App、官网和小程序免费使用;
5月11日,智谱大模型官宣降价,入门级产品GLM-3 Turbo模型,百万Tokens调用价格从5元降至1元,降幅高达80%;
5月15日,字节发布豆包大模型,比行业平均价格便宜99.3%,推动大模型从“以分计价”,进入“以厘计价”阶段;
5月21日,阿里宣布9款大模型降价,百度宣布文心大模型两大主力模型ERNIE Speed、ERNIE Lite全面免费时代。
5月22日,科大讯飞宣布讯飞星火Lite API永久免费开放,腾讯云公布大模型升级方案,主力模型之一调整为免费。
国内大模型厂商,迎来对B端和C端的全面降价甚至免费。
不仅是国内厂商宣布降价,近日,OpenAI也发布了对C端用户的GPT-4o免费版及B端的降价。
那么,大模型厂商为什么会降价?降价之后靠什么变现?除了降价,大模型厂商还有什么路可以走?本文将回答围绕以上三个问题展开讨论。
一、降价,为数不多可以出的牌
国内外大模型厂商降价的驱动力不完全相同:OpenAI可以出的牌有很多,而卷价格是国内厂商为数不多可以出且必须跟进的牌。
先来看国外的大模型厂商。
OpenAI在降价的同时,也在不断自我超越。
去年11月,OpenAI率先开始降价,升级后的ChatGPT-4 Turbo,速度比ChatGPT速度更快,而且价格比之前下降了近7成,同时OpenAI发布GPT-s商店,开发者可以在其平台上开发并上线AI应用,供用户使用。
今年5月14日,OpenAI发布新一代GPT-4o,功能上全面超越上一代,而且API价格再下降50%。
去年底,谷歌发布的Gemini,在多方面的性能超越ChatGPT,还支持视频输入和视频搜索,同时宣布Gemini Ultra可免费使用。
OpenAI在大模型上具有先发优势,也最早开始通过大模型实现可观的营收,截至去年10月,其收入已达13亿美元,相比上一年2800万美元的收入增长了45倍,所以OpenAI有降价扩大市场份额的资本。
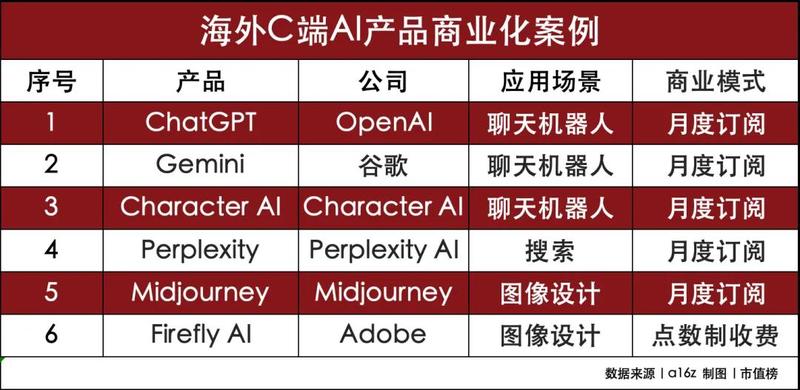
今年3月,美国风险投资机构a16z发布的报告显示,排名前三的都是AI聊天机器人,ChatGPT仍是C端应用顶流,机构预计今年ChatGPT的收入是10亿美元。
排名第二的是谷歌Gemini,对C端则采取的是免费模式,所以C端暂时还未实现变现,不过在B端,5月谷歌宣布调用API开始收费。Gemini虽然未直接对谷歌贡献收入,但是间接贡献了收入,谷歌一季报提到,Gemini为谷歌的搜索业务和云业务提升了收入水平。
再来看国内的大模型厂商。
国内的大模型厂商也在不断进步,也希望通过提供更好的综合使用效果,而不是通过降价保持竞争优势。
但现实是,几天前还在持这一观点的百度,几天后就宣布两大模型免费了。
现在还持这个观点的有李开复,他的零一万物模型目前还没有加入降价战场,但他也认可“行业每年降低10倍推理成本是可以期待的,而且也是必然发生的”。
“提供更好的综合能力和使用效果”这条路不是走不通,而是解决不了当前大模型厂商面临的主要矛盾。
主要矛盾是什么?
是需要更多人应用。
现在国内的大模型,都可能在某些方面领先甚至是拔尖,但没有哪一家是公认的“领头羊”。而大模型的发展很容易出现二八分化,现在不争,以后可能就没机会了。
举个例子,针对C端用户的通用场景有很多,比如打车、订票、购物等等,现在,我们的操作是打开一个个APP或者小程序;在AI发展的过程中,我们需要的可能是一个个生活助理;而在终极形态下,我们需要的是一个管家,可以根据我们的日程、预算,安排好是打车还是其他出行方式,根据近期的口味偏好提前订好餐厅。
这就意味着在C端场景下,必然会有大的整合,应用的整合甚至是大模型厂商之间的整合。
谁的大模型能调用的应用多,谁就更有竞争优势,就更可能是整合方。
所以现在的大模型厂商在降低API调用成本,希望开发者能在自己的生态上开发出好用的AI应用,就算免费、甚至是补贴也要争。
B端应用可能会好一些,毕竟行业之间差异大,容得下更多的模型,这又涉及到另一个问题:数据。
数据是AI三要素之一。大模型通过应用与足够多的用户互动,才有机会走上价格战以外的路。
二、 都免费了还怎么变现?
大模型服务是典型的规模经济,当使用的企业和用户越多,则越能摊薄企业的研发和算力成本,在可预见的未来,算力价格会持续下降,所以这也给了国内大模型厂商降价的底气。
王小川在回应大模型厂商价格战时也表示:降价意味着,大家实在是太看好这个时代的前景了,不愿失去,侧面反映大家对这个时代AI的能力是有足够多憧憬的。
大模型厂商变现有两个途径:
第一,给企业提供模型服务,包括调用API,项目制本地模型落地等。
大模型厂商,目前向B端收取调用收费包括按照时间段、按调用量收费以及各种包含硬件的一站式解决方案等。
OpenAI推出30款左右可供用户调用的大模型,分别包括GPT-3.5 Turbo、GPT-4、GPT-4 Turbo、图像模型、音频模型等,其他厂商通过API实现调用。
实现标准化的模型调用服务,即MaaS(模型即服务),美国从SaaS到MaaS,已形成较大规模的标准化市场。国内的标准化SaaS规模还很小,大多还只是集成式的项目模式,这样的模式成本高,利润小。
国内的云厂商,正在从项目制转向标准化的SaaS服务,而大模型正是一次机会,所以大模型厂商争相降价抢夺市场。
第二,模型厂商自己做应用实现变现,探索更多的可能。
OpenAI不仅给其他应用厂商开放API,而且有自己的聊天机器人ChatGPT,也已成为现象级应用,这是国内厂商目前还不具备的能力。
同时,OpenAI上线了GPTs,从此前的插件模式升级为与开发者共享收益的模式,虽然GPTs反响一般,但提供了变现的思路。
上文提到的榜单,除了前两名的聊天机器人外,后面排第三的Character AI,便是通过调用OpenAI提供的API,利用OpenAI大模型能力开发出了受欢迎的聊天机器人。
CharacterAI,可以扮演数百名虚拟人物,既可以满足用户的情感类需求,也可以满足用户的工具型需求。比如AI可以扮演拿破仑、马斯克、居里夫人等,与用户聊天,也可以扮演心理咨询师、图书管理员、英文老师等角色,提供健身指导、知识传授等服务。
三、 价格战之外的路还有机会走吗?
场景端革新,是中国应用市场后来居上的传统优势,同时也具有反哺大模型能力的作用。
国外应用厂商大多是小而美的应用,而中国则更多的是大而全。
比如微信、支付宝、抖音等平台,除了核心的社交、支付、短视频等功能之外,还有集成了购物、支付、社交、娱乐等功能。国外的应用大多偏工具属性,比如Facebook、亚马逊、谷歌等,分别注重社交、购物和搜索,很少在应用当中集成其他功能。
第一,国内模型厂商,可根据各个大厂的优势,提供不同特色的模型。
前面我们提到,在AI发展的过程中,会出现一个个AI助理,开始的功能比较基础,是一个辅助的角色,被称为Copilot,主要是根据某个情景,提出解决问题的指导、建议,停留在“懂怎么做”的层面,现在AI助理有了更强的执行能力,进化到“会做”“能做”层面,也被称为AI Agent,可以直接解决某些问题,以后可能是一个管家可以调度很多个AI Agent,完成更复杂的任务。
就像真正提供服务的小程序折叠在微信、抖音、支付宝身后一样,Agent也可以折叠在管家后面。
在迈向终局的过程中,支付宝、抖音都可以利用其折叠能力,去调用目前的小程序,让用户通过AI告诉每个小程序执行我们的需求。
比如支付宝在灰度测试中的AI智能助理,如果早上起来对它说,半小时后打车上班,AI小助理就会调用「滴滴」的接口,帮我们预约好车。
同理,美团也可以利用生态,实现预定餐厅、买好电影票、制定路线等。
未来,大厂也可以通过开发各自的生态,更多的应用厂商,研发更多的特色应用,这是国内厂商的潜力。
第二,通过对国外先进模型的模仿和自研,实现能力的快速提升。
OpenAI最新的GPT-4o模型可以实现多模态包括音频、视觉和文本的推理,而且还可以对三者进行组合输出,平均响应时间仅为320毫秒,反应速度与人类相近。
所以,很多头部软硬件开发厂商包括微软、Salesforce、Adobe,会选择与OpenAI合作,将模型能力集成到各自的应用软件当中。
谷歌的Gemini,在搜索能力的强化上表现突出,当你录制一段视频搜索或者使用AI搜索时,它都能准确理解你的意图,通过搜索结果形成一份报告,甚至是对用户忽略问题的猜测。
有的国外大模型是开源的,也是国内大模型厂商可以利用的机会。
通过各个大厂也都在积极自研,国内的大模型厂商,一方面需要通过提升大模型能力,吸引更多的厂商入驻;另一方面,也可以依据自身做AI应用的经验,建立生态,帮助厂商研发出现象级应用。
以“应用工厂”著称的字节,通过应用的人海战术、赛马机制,让更多的应用跑出来,从而不仅让抖音成为中国现象级应用,而且Tiktok也力压硅谷各大厂成为海外现象级应用。字节虽然不是推荐引擎的首创,但是在应用场景和流量模式的创新,让抖音和Tiktok都获得了成功。
国内厂商的总体技术能力可能不及国外厂商,但AI的能力和边界,不完全由技术能力决定。